
协同过滤
协同过滤
协同过滤算法的主要功能是预测和推荐。协同过滤推荐算法分为两类,分别是基于用户的协同过滤算法(user-based CF),和基于物品的协同过滤算法(item-based CF)。
协同过滤作为一种经典的推荐算法种类,在工业界应用广泛,它的优点很多,模型通用性强,不需要太多对应数据领域的专业知识,工程实现简单,效果也不错。这些都是它流行的原因。
基于用户的协同过滤算法是通过用户的历史行为数据发现用户对物品喜爱程度,并对这些喜好进行度量打分。通过不同用户对商品态度和偏好程度计算用户之间的关系,对有相同喜好的用户间进行商品推荐。
基于物品的协同过滤算法是通过计算不同用户对不同物品的评分获得物品间的相关关系。基于物品间的相关性对用户进行相似物品的推荐。
相似性度量标准:常用的相似性度量标准采用欧几里德距离和皮尔逊相关系数。
欧几里德距离:
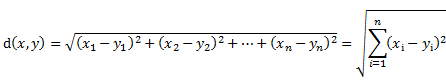
皮尔逊相关系数:
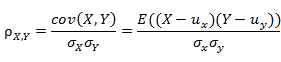
相关应用
协同过滤算法的主要功能是预测和推荐。经常被用来分辨某位特定顾客可能感兴趣的东西,并给他推荐相应的产品,而这些结论主要来自于对其他相似顾客对哪些产品感兴趣的分析。协同过滤以其出色的速度和健壮性,广泛应用于互联网等领域。
优缺点
优点:能够过滤基于内容的机器难以进行分析的信息;能对一些复杂、难以表达的概念进行过滤;推荐的新颖性。
缺点:存在稀疏性问题,如用户对商品的评价特别少,使得基于用户评价的用户间相似性计算可能不够准确;随着用户和商品的增多,系统的性能会越来越低;存在最初评价问题,即没有用户对某一商品加以评价,则这个商品便不能被推荐。
 wechat
wechat alipay
alipay
评论



