Flink-Watermark机制 | 字数总计: 2.2k | 阅读时长: 9分钟 | 阅读量: |
watermark简介 watermark的概念 watermark是一种衡量Event Time进展的机制,它是数据本身的一个隐藏属性。通常基于Event Time的数据,自身都包含一个timestamp,例如1472693399700(2016-09-01 09:29:59.700),而这条数据的watermark时间则可能是:
watermark(1472693399700 ) = 1472693396700 (2016 -09-01 09:29 :56.700 )
这条数据的watermark时间是什么含义呢?即:timestamp小于1472693396700(2016-09-01 09:29:56.700)的数据,都已经到达了
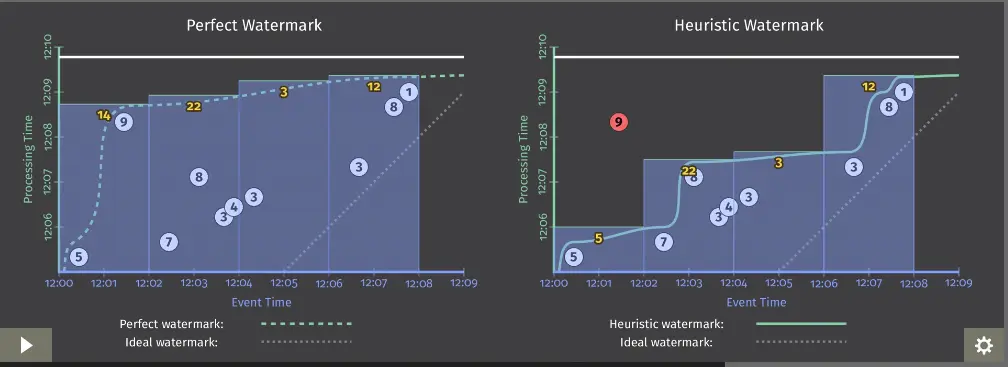
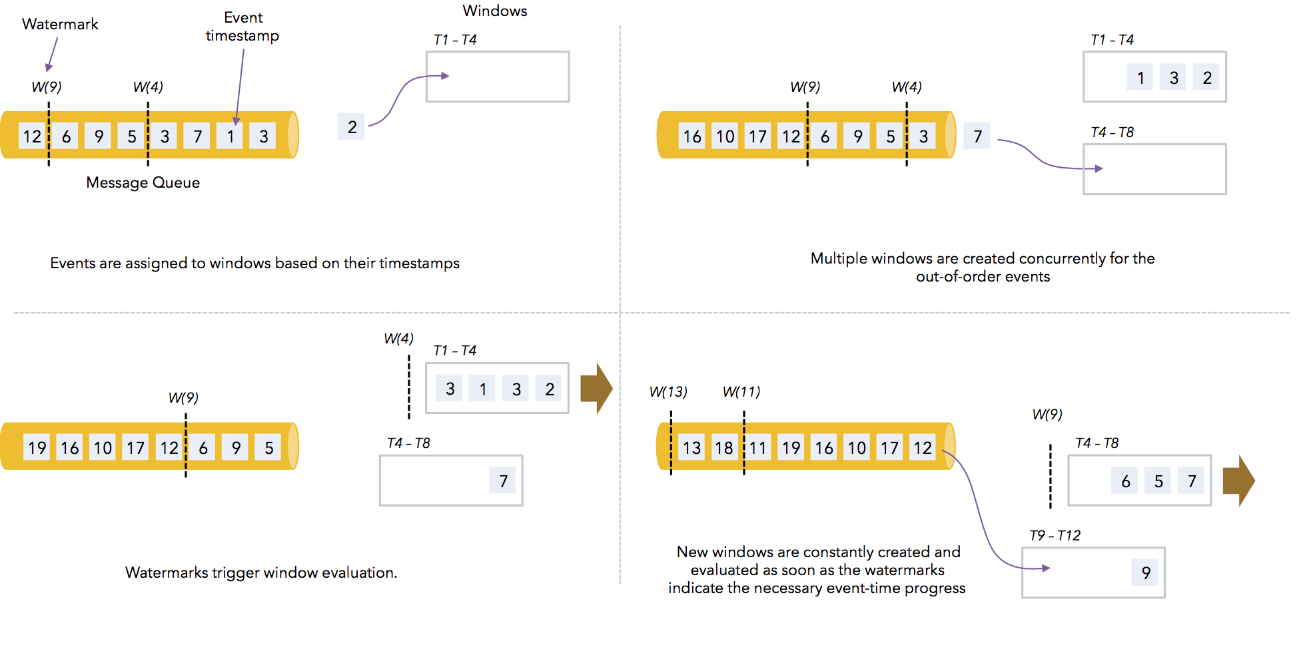
watermark有什么用? watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用watermark机制结合window来实现。
我们知道,流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的。虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、背压等原因,导致乱序的产生(out-of-order或者说late element)。
但是对于late element,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark。
watermark如何分配? 通常,在接收到source的数据后,应该立刻生成watermark;但是,也可以在source后,应用简单的map或者filter操作,然后再生成watermark。生成watermark的方式主要有2大类:
(1 ):With Periodic Watermarks (2 ) :With Punctuated Watermarks
第一种可以定义一个最大允许乱序的时间,这种情况应用较多。 代码如下:
class BoundedOutOfOrdernessGenerator extends AssignerWithPeriodicWatermarks [MyEvent] { val maxOutOfOrderness = 3500L ; var currentMaxTimestamp: Long; override def extractTimestamp (element: MyEvent, previousElementTimestamp: Long) : Long = { val timestamp = element.getCreationTime() currentMaxTimestamp = max(timestamp, currentMaxTimestamp) timestamp; } override def getCurrentWatermark () : Watermark = { new Watermark (currentMaxTimestamp - maxOutOfOrderness); } }
程序中有一个extractTimestamp方法,就是根据数据本身的Event time来获取;还有一个getCurrentWatermar方法,是用currentMaxTimestamp - maxOutOfOrderness来获取的。
watermark代码 public static void main (String[] args) throws Exception { StreamExecutionEnvironment environment=StreamExecutionEnvironment.getExecutionEnvironment(); environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); Properties properties = new Properties (); properties.setProperty("bootstrap.servers" , "localhost:9092" ); properties.setProperty("zookeeper.connect" , "localhost:2181" ); properties.setProperty("group.id" , "test" ); FlinkKafkaConsumer011<String> myConsumer = new FlinkKafkaConsumer011 <String>("test" , new SimpleStringSchema (),properties); DataStream<String> stream = environment.addSource(myConsumer); DataStream<Tuple2<String,Long>> inputMap = stream.map(new MapFunction <String, Tuple2<String, Long>>() { @Override public Tuple2<String, Long> map (String s) throws Exception { String [] arr = s.split("," ); return new Tuple2 <>(arr[0 ],Long.parseLong(arr[1 ])); } }); DataStream<Tuple2<String,Long>> watermarkStream = inputMap.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks <Tuple2<String, Long>>() { Long currentMaxTimeStamp = 0L ; final Long maxOutOfOrderness = 10000L ; SimpleDateFormat sdf = new SimpleDateFormat ("yyyy-MM-dd HH:mm:ss.SSS" ); @Nullable @Override public Watermark getCurrentWatermark () { return new Watermark (currentMaxTimeStamp-maxOutOfOrderness); } @Override public long extractTimestamp (Tuple2<String, Long> element, long previousTimeStamp) { long timestamp = element.f1; currentMaxTimeStamp = Math.max(currentMaxTimeStamp,timestamp); assert getCurrentWatermark () != null ; System.out.println("键值 :" +element.f0+",事件时间:[ " +sdf.format(element.f1)+" ],currentMaxTimestamp:[ " + sdf.format(currentMaxTimeStamp)+" ],水印时间:[ " +sdf.format(getCurrentWatermark().getTimestamp())+" ]" ); return timestamp; } }); DataStream<String> window = watermarkStream.keyBy(0 ) .window(TumblingEventTimeWindows.of(Time.seconds(3 ))) .apply(new WindowFunction <Tuple2<String, Long>, String, Tuple, TimeWindow>() { @Override public void apply (Tuple tuple, TimeWindow timeWindow, Iterable<Tuple2<String, Long>> iterable, Collector<String> collector) throws Exception { String key = tuple.toString(); List<Long> arrayList = new ArrayList <Long>(); Iterator<Tuple2<String, Long>> it = iterable.iterator(); while (it.hasNext()) { Tuple2<String, Long> next = it.next(); arrayList.add(next.f1); } Collections.sort(arrayList); SimpleDateFormat sdf = new SimpleDateFormat ("yyyy-MM-dd HH:mm:ss.SSS" ); String result = "\n 键值 : " + key + "\n 触发窗内数据个数 : " + arrayList.size() + "\n 触发窗起始数据: " + sdf.format(arrayList.get(0 )) + "\n 触发窗最后(可能是延时)数据:" + sdf.format(arrayList.get(arrayList.size() - 1 )) + "\n 实际窗起始和结束时间: " + sdf.format(timeWindow.getStart()) + "《----》" + sdf.format(timeWindow.getEnd()) + " \n \n " ; collector.collect(result); } }); window.print(); environment.execute("eventtime-watermark" ); }
接收kafka数据
将每行数据按照字符分隔,每行map成一个tuple类型(code,time)
抽取timestamp生成watermark。并打印(code,time,格式化的time,currentMaxTimestamp,currentMaxTimestamp的格式化时间,watermark时间)。
event time每隔3秒触发一次窗口,输出(code,窗口内元素个数,窗口内最早元素的时间,窗口内最晚元素的时间,窗口自身开始时间,窗口自身结束时间)
注意:new AssignerWithPeriodicWatermarks[(String,Long)中有抽取timestamp和生成watermark2个方法,在执行时,它是先抽取timestamp,后生成watermark,因此我们在这里print的watermark时间,其实是上一条的watermark时间.
watermark实验 正常数据 在上述代码中设置了允许最大的延迟时间是10s
输入:
>000001 ,1461756862000 >000001 ,1461756866000 >000001 ,1461756872000
输出:
键值 :000001 ,事件时间:[ 2016 -04 -27 19 :34 :22.000 ],currentMaxTimestamp:[ 2016 -04 -27 19 :34 :22.000 ],水印时间:[ 2016 -04 -27 19 :34 :12.000 ] 键值 :000001 ,事件时间:[ 2016 -04 -27 19 :34 :26.000 ],currentMaxTimestamp:[ 2016 -04 -27 19 :34 :26.000 ],水印时间:[ 2016 -04 -27 19 :34 :16.000 ] 键值 :000001 ,事件时间:[ 2016 -04 -27 19 :34 :32.000 ],currentMaxTimestamp:[ 2016 -04 -27 19 :34 :32.000 ],水印时间:[ 2016 -04 -27 19 :34 :22.000 ]
我们可以看到输入已经达到10s,等于第一条数据的Event Time了,却没有触发window窗口计算,此时再输入:
>000001 ,1461756862000 >000001 ,1461756866000 >000001 ,1461756872000 >000001 ,1461756874000
输出:
键值 :000001 ,事件时间:[ 2016 -04 -27 19 :34 :34.000 ],currentMaxTimestamp:[ 2016 -04 -27 19 :34 :34.000 ],水印时间:[ 2016 -04 -27 19 :34 :24.000 ] 3 > 键值 : (000001 ) 触发窗内数据个数 : 1 触发窗起始数据: 2016 -04 -27 19 :34 :22.000 触发窗最后(可能是延时)数据:2016 -04 -27 19 :34 :22.000 实际窗起始和结束时间: 2016 -04 -27 19 :34 :21.000 《----》2016 -04 -27 19 :34 :24.000
此时watermark的时间2016-04-27 19:34:24.000是可以看到已经触发窗口计算了,因此得到一个结论,当watermark时间 >= window_end_time的时候才会触发窗口计算,需要注意的是watermark与key无关,是系统设定的,即使是不同的key,只要是时间达到了即可触发。
window的触发条件:
只有同时满足上述条件才会触发窗口计算。
乱序数据 我们此时输入一个乱序的数据,此时watermark的时间2016-04-27 19:34:24.000,我们输入一个:
输出:
键值 :000001 ,事件时间:[ 2016 -04 -27 19 :34 :31.000 ],currentMaxTimestamp:[ 2016 -04 -27 19 :34 :34.000 ],水印时间:[ 2016 -04 -27 19 :34 :24.000 ]
可以看到,虽然我们输入了一个19:34:31的数据,但是currentMaxTimestamp和watermark都没变。此时,按照我们上面提到的公式:watermark时间(19:34:24) < window_end_time(19:34:27),因此不能触发window。此时再输入一条数据:
输出:
键值 :000001 ,事件时间:[ 2016 -04 -27 19 :34 :41.000 ],currentMaxTimestamp:[ 2016 -04 -27 19 :34 :41.000 ],水印时间:[ 2016 -04 -27 19 :34 :31.000 ] 3 > 键值 : (000001 ) 触发窗内数据个数 : 1 触发窗起始数据: 2016 -04 -27 19 :34 :26.000 触发窗最后(可能是延时)数据:2016 -04 -27 19 :34 :26.000 实际窗起始和结束时间: 2016 -04 -27 19 :34 :24.000 《----》2016 -04 -27 19 :34 :27.000
可以看到 2016-04-27 19:34:31.000>2016-04-27 19:34:27.000,此时watermark时间大于窗口结束时间了,因此会触发窗口计算,并更新最新的窗口结束位置以及最新的watermark。
乱序很多的数据 我们输入一个乱序很多的(其实只要Event Time < watermark时间)数据来测试下:
输入:
>000001 ,1461756862000 >000001 ,1461756866000 >000001 ,1461756872000 >000001 ,1461756874000 >000001 ,1461756871000 >000001 ,1461756881000 >000001 ,1461756841000
此时Event Time < watermark时间,所以来一条就触发一个window。
总结 Flink如何处理乱序?
Flink何时触发window?
watermark时间 > Event Time(对于late element太多的数据而言) watermark时间 >= window_end_time(对于out-of-order以及正常的数据而言 在[window_start_time,window_end_time)中有数据存在
Flink应该如何设置最大乱序时间?
这个要结合自己的业务以及数据情况去设置。如果maxOutOfOrderness设置的太小,而自身数据发送时由于网络等原因导致乱序或者late太多,那么最终的结果就是会有很多单条的数据在window中被触发,数据的正确性影响太大。

 wechat
wechat alipay
alipay








