
自适应提升算法
AdaBoost
自适应提升(AdaBoost:Adaptive Boosting)算法是基于概率近似正确的学习模型下提出的一种提升算法。在分类问题中,AdaBoost通过修改训练样本的权值分布,学习多个弱分类器,并将这些分类器进行线性组合,构成一个强分类器,提高分类性能。其中强分类器可理解为分类精确度高的算法,弱分类器可理解为分类精度低的算法,一般AdaBoost算法是弱分类器的线性组合为:
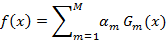
AdaBoost算法的特点是通过迭代每次学习一个基本分类器(即弱分类器)。每次迭代中,提高那些被前一轮分类器错误分类数据样本的权值,而降低那些被正确分类的数据样本的权值。最后算法将基本分类器的线性组合作为强分类器,其中给分类误差率小的基本分类器以大的权值,给分类误差率大的基本分类器以小的权值。其中极小化损失函数表达式为:
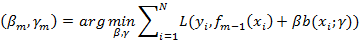
算法原理
假设给定一个二分类的训练数据集T={(x1,y1),(x2,y2),…,(xn,yn)};其中,每个样本点由实例与标记组成。实例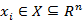
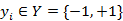 其中X是实例空间,Y是标记集合。AdaBoost算法的原理如下:
其中X是实例空间,Y是标记集合。AdaBoost算法的原理如下:
输入:训练数据集T={(x1,y1),(x2,y2),…,(xn,yn)};其中
输出:最终的分类器G(x)
(1)初始化训练数据集的权值分布
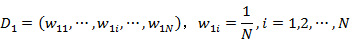
(2)对于m=1,2,…,M
(a)使用具有权值分布Dm的训练数据集学习,得到基本分类器
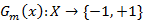
(b)计算Gm(x)在训练数据集上的分类误差率
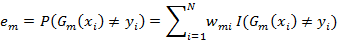
©计算Gm(x)的系数
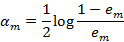
(d)更新训练数据集的权值分布
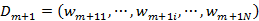
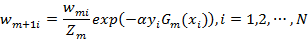
其中Zm是规范化因子
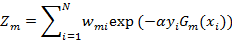
(3)构建基本分类器的线性组合
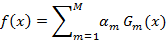
得到最终分类器为
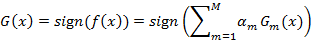
相关应用
AdaBoost算法主要用于分类问题。它是通过改变训练样本的权重,学习多个分类器,并将这些分类器线性组合,以提高分类的性能。它的应用范围非常广泛,可用于二分类或多分类的应用场景,可用于特征选择等。
优点
优点:分类精度很高的分类器;弱分类器容易构造;算法简单,不用做特征筛选;不用担心过拟合
 wechat
wechat alipay
alipay



