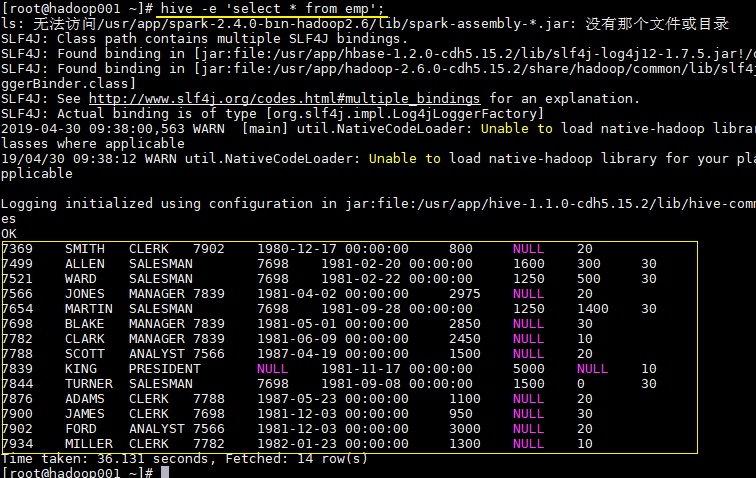
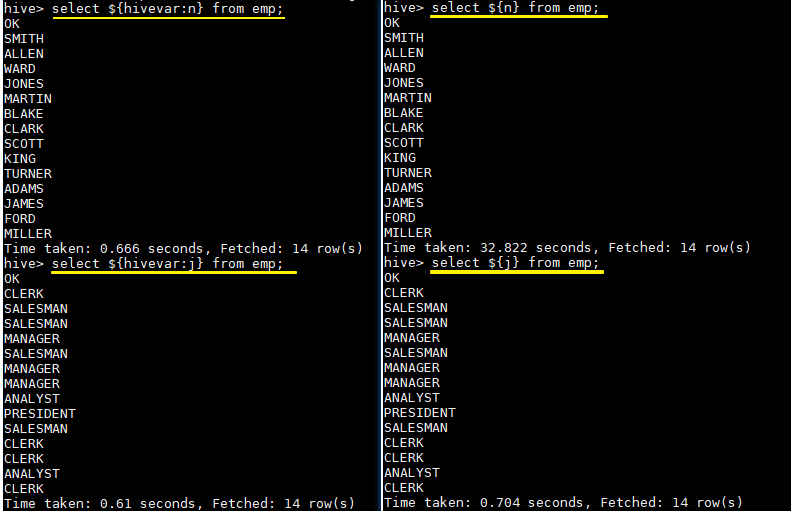
usage: hive -d,--define <key=value> Variable subsitution to apply to hive commands. e.g. -d A=B or --define A=B --定义用户自定义变量 --database <databasename> Specify the database to use -- 指定使用的数据库 -e <quoted-query-string> SQL from command line -- 执行指定的 SQL -f <filename> SQL from files --执行 SQL 脚本 -H,--help Print help information -- 打印帮助信息 --hiveconf <property=value> Use value for given property --自定义配置 --hivevar <key=value> Variable subsitution to apply to hive --自定义变量 commands. e.g. --hivevar A=B -i <filename> Initialization SQL file --在进入交互模式之前运行初始化脚本 -S,--silent Silent mode in interactive shell --静默模式 -v,--verbose Verbose mode (echo executed SQL to the console) --详细模式
Usage: java org.apache.hive.cli.beeline.BeeLine -u<database url> the JDBC URL to connect to -rreconnect to last saved connect url (in conjunction with !save) -n<username> the username to connect as -p<password> the password to connect as -d<driver class> the driver class to use -i<init file> script file for initialization -e<query> query that should be executed -f<exec file> script file that should be executed -w(or) --password-file <password file> the password file to read password from --hiveconfproperty=value Use value for given property --hivevarname=value hive variable name and value Thisis Hive specific settings in which variables canbe set at session level and referenced in Hive commandsor queries. --property-file=<property-file> the file to read connection properties (url, driver, user, password) from --color=[true/false] control whether color is used for display --showHeader=[true/false] show column names in query results --headerInterval=ROWS; the interval between which heades are displayed --fastConnect=[true/false] skip building table/column list for tab-completion --autoCommit=[true/false] enable/disable automatic transaction commit --verbose=[true/false] show verbose error messages and debug info --showWarnings=[true/false] display connection warnings --showNestedErrs=[true/false] display nested errors --numberFormat=[pattern] format numbers using DecimalFormat pattern --force=[true/false] continue running script even after errors --maxWidth=MAXWIDTH the maximum width of the terminal --maxColumnWidth=MAXCOLWIDTH the maximum width to use when displaying columns --silent=[true/false] be more silent --autosave=[true/false] automatically save preferences --outputformat=[table/vertical/csv2/tsv2/dsv/csv/tsv] format mode for result display --incrementalBufferRows=NUMROWS the number of rows to buffer when printing rows on stdout, defaultsto 1000; only applicable if --incremental=true and--outputformat=table --truncateTable=[true/false] truncate table column when it exceeds length --delimiterForDSV=DELIMITER specify the delimiter for delimiter-separated values output format (default: |) --isolation=LEVEL set the transaction isolation level --nullemptystring=[true/false] set to true to get historic behavior of printing null as empty string --maxHistoryRows=MAXHISTORYROWS The maximum number of rows to store beeline history. --convertBinaryArrayToString=[true/false] display binary column data as string or as byte array --helpdisplay this message

 wechat
wechat alipay
alipay







