
FP-growth算法
FP-growth算法(FP-Growth Algorithm)
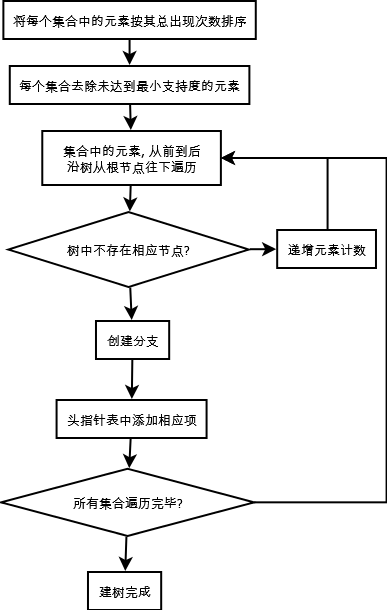
FP-growth算法是基于Apriori原理的,通过将数据集存储在FP(Frequent Pattern)树上发现频繁项集,但不能发现数据之间的关联规则。FP-growth算法只需要对数据库进行两次扫描,而Apriori算法在求每个潜在的频繁项集时都需要扫描一次数据集,所以说Apriori算法是高效的。其中算法发现频繁项集的过程是:
- 1.构建FP树;
- 2.从FP树中挖掘频繁项集。
构建FP树
FP表示的是频繁模式,其通过链接来连接相似元素,被连起来的元素可以看成是一个链表。将事务数据表中的各个事务对应的数据项按照支持度排序后,把每个事务中的数据项按降序依次插入到一棵以 NULL为根节点的树中,同时在每个结点处记录该结点出现的支持度。
FP-growth算法的流程为:首先构造FP树,然后利用它来挖掘频繁项集。在构造FP树时,需要对数据集扫描两边,第一遍扫描用来统计频率,第二遍扫描至考虑频繁项集。下面举例对FP树加以说明。
假设存在的一个事务数据样例为,构建FP树的步骤如下:
| 事务ID | 事务中的元素 |
|---|---|
| 001 | r,z,h,j,p |
| 002 | z,y,x,w,v,u,t,s |
| 003 | z |
| 004 | r,x,n,o,s |
| 005 | y,r,x,z,q,t,p |
| 006 | y,z,x,e,q,s,t,m |
结合Apriori算法中最小支持度的阈值,在此将最小支持度定义为3,结合上表中的数据,那些不满足最小支持度要求的将不会出现在最后的FP树中,据此构建FP树,并采用一个头指针表来指向给定类型的第一个实例,快速访问FP树中的所有元素,构建的带头指针的FP树如下:
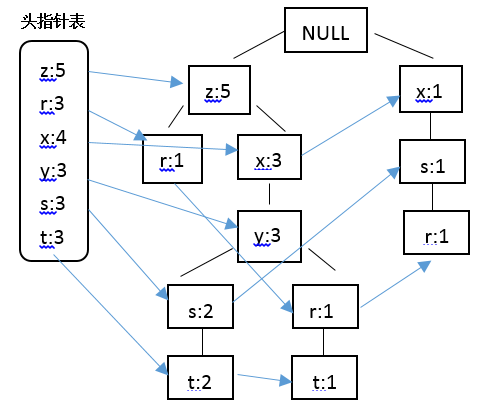
结合绘制的带头指针表的FP树,对表中数据进行过滤,排序如下:
| 事务ID | 事务ID | 过滤和重排序后的事务 |
|---|---|---|
| 001 | r,z,h,j,p | z,r |
| 002 | z,y,x,w,v,u,t,s | z,x,y,s,t |
| 003 | z | z |
| 004 | r,x,n,o,s | x,s,r |
| 005 | y,r,x,z,q,t,p | z,x,y,r,t |
| 006 | y,z,x,e,q,s,t,m | z,x,y,s,t |
在对数据项过滤排序了之后,就可以构建FP树了,从NULL开始,向其中不断添加过滤排序后的频繁项集。过程可表示为:
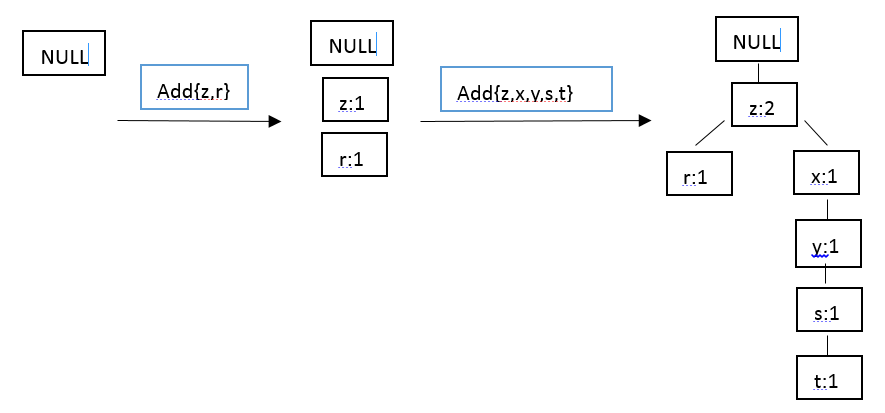
因而我们可以实现FP树的构建,我们知道,在第二次扫描数据集时会构建一棵FP树,并采用一个容器来保存树。首先创建一个类来保存树的每一个节点:
from numpy import * |
这样,FP树对应的数据结构就建好了,现在就可以构建FP树了,FP树的构建函数如下:
#FP构建函数 |
在应用示例之前还需要一个真正的数据集,结合之前的数据自定义数据集:
def loadSimpDat(): |
结果:
simpDat = loadSimpDat() |
这样就构建了FP树,接下来就是使用它来进行频繁项集的挖掘。
从FP树中挖掘频繁项集
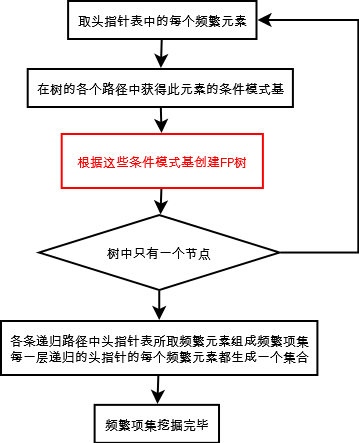
在构建了FP树之后,就可以抽取频繁项集了,这里的思想和Apriori算法大致类似,首先从氮元素项集合开始,然后在此基础上逐步构建更大的集合。大致分为三个步骤:
1.从FP树中获得条件模式基;
2.利用条件模式基,构建一个条件FP树;
3.迭代重复1和2,直到树包含一个元素项为止。首先,获取条件模式基。条件模式基是以所查找元素项为结尾的路径集合,表示的是所查找的元素项与树根节点之间的所有内容。结合构建FP树绘制的图,r的前缀路径就是{x,s}、{z,x,y}和{z},其中的每条前缀路径都与一个计数值有关,该计数值表示的是每条路径上r的数目。为了得到这些前缀路径,结合之前所得到的头指针表,头指针表中包含相同类型元素链表的起始指针,根据每一个元素项都可以上溯到这棵树直到根节点为止。该过程对应的如下:
def ascendTree(leafNode, prefixPath): #ascends from leaf node to root |
运行示例,与所给数据一致。接下来就可以创建条件FP树了。对于每一个频繁项,都需要创建一棵条件FP树,使用刚才创建的条件模式基作为输入,采用相同的建树代码来构建树,相应的递归发现频繁项、发现条件模式基和另外的条件树。对应的递归查找频繁项集的函数如下:
def mineTree(inTree, headerTable, minSup, preFix, freqItemList): |
结合之前的数据验证发现没有错误。
应用示例
# -*- coding: utf-8 -* |
 wechat
wechat alipay
alipay





