class Apriori():
def __init__(self):
pass
'''
关联分析的目标包括两项:发现频繁项集和发现关联规则
'''
'''
频繁项集:
对于包含N种物品的数据集共有2^N-1种项集组合。
支持度(support)
一个项集的支持度被定义为数据集中包含该项集的记录所占的比例。
Apriori算法:如果某个项集是频繁的,那么它的所有子集也是频繁的。
如果一个项集是非频繁集,那么它的所有超集也是非频繁集。
'''
def _createC1(self, dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if [item] not in C1:
C1.append([item])
C1.sort()
return map(frozenset, C1)
def _scanD(self, D, Ck, minSupport=0.5):
ssCnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid):
if can in ssCnt:
ssCnt[can] += 1
else:
ssCnt[can] = 1
numItems = len(D)
retList = []
supportK = {}
for key in ssCnt:
support = ssCnt[key]/float(numItems)
if support >= minSupport:
retList.append(key)
supportK[key] = support
return retList, supportK
def aprioriGen(self, Lk, k):
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1, lenLk):
L1 = list(Lk[i])[:k-2]
L2 = list(Lk[j])[:k-2]
L1.sort()
L2.sort()
if L1 == L2:
retList.append(Lk[i] | Lk[j])
return retList
def apriori(self, dataSet, minSupport=0.5):
D = map(set, dataSet)
C1 = self._createC1(dataSet)
L1, supp1 = self._scanD(D, C1, minSupport)
L = []
supportData = {}
L.append(L1)
supportData.update(supp1)
k = 2
while len(L[k-2]) > 1:
Ck = self.aprioriGen(L[k-2], k)
Lk, suppK = self._scanD(D, Ck, minSupport)
L.append(Lk)
supportData.update(suppK)
k += 1
return L, supportData
'''
关联规则:→
可信度(confidence):也称置信度
可信度(尿布→葡萄酒) = 支持度({尿布,葡萄酒})/支持度({尿布})
如果某条规则并不满足最小可信度要求,那么该规则的所有子集也不会满足最小可信度要求。
'''
def _calcConf(self, freqSet, H, supportData, brl, minConf=0.7):
prunedH = []
for conseq in H:
conf = supportData[freqSet]/supportData[freqSet-conseq]
if conf >= minConf:
print freqSet-conseq, '-->', conseq, 'conf:', conf
brl.append((freqSet-conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
def _rulesFromConseq(self, freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
if len(freqSet) > (m+1):
Hmp1 = self.aprioriGen(H, m+1)
Hmp = self._calcConf(freqSet, Hmp1, supportData, brl, minConf)
if len(Hmp) > 1:
self._rulesFromConseq(freqSet, Hmp, supportData, brl, minConf)
def generateRules(self, L, supportData, minConf=0.7):
bigRuleList = []
for i in range(1, len(L)):
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if i > 1:
self._rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
else:
self._calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
def loadDataSet():
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
if __name__ == '__main__':
dataSet = loadDataSet()
ap = Apriori()
L, suppData = ap.apriori(dataSet, minSupport=0.5)
print L
print suppData
rules = ap.generateRules(L, suppData, minConf=0.6)
print rules
|

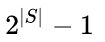 个可能的子集之后才寻找任意最大子集S。
个可能的子集之后才寻找任意最大子集S。 wechat
wechat alipay
alipay



