import pandas as pd from math import log from anytree import Node, RenderTree from anytree.dotexport import RenderTreeGraph
defcreate_decision_tree_id3(df, y_col): # 计算H(C) defh_value(): h = 0 for v in df.groupby(y_col).size().div(len(df)): h += -v * log(v, 2)
return h
# 计算某一个属性的信息增益 defget_info_gain_byc(column, df, y_col): # 计算p(column) probs = df.groupby(column).size().div(len(df)) v = 0 for index1, v1 in probs.iteritems(): tmp_df = df[df[column] == index1] tmp_probs = tmp_df.groupby(y_col).size().div(len(tmp_df)) tmp_v = 0 for v2 in tmp_probs: # 计算H(C|X=xi) tmp_v += -v2 * log(v2, 2) # 计算H(y_col|column) v += v1 * tmp_v return v
# 获取拥有最大信息增益的属性 defget_max_info_gain(df, y_col): d = {} h = h_value() for c infilter(lambda c: c != y_col, df.columns): # 计算H(y_col) - H(y_col|column) d[c] = h - get_info_gain_byc(c, df, y_col)

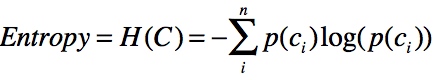
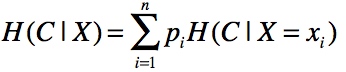
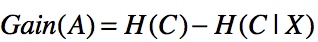
 wechat
wechat alipay
alipay







