
学习矢量化
学习矢量化
学习矢量量化(Learning Vector Quantization,简称LVQ),与1988年提出的一种用于模式分类的有监督学习算法,是一种结构简单、功能强大的有监督式神经网络分类算法。典型的学习矢量量化算法有:LVQ1、LVQ2、LVQ3,其中,前两种算法应用较为广泛,尤其以LVQ2应用最为广泛和有效。
学习矢量量化是一种结构简单、功能强大的有监督式神经网络分类方法。作为一种最近邻原型分类器,LVQ在训练过程中通过对神经元权向量(原型向量)的不断更新,对其学习率的不断调整,能够使不同类别权向量之间的边界逐步收敛至贝叶斯分类边界。算法中,对获胜神经元(最近邻权向量)的选取是通过计算输入样本和权向量之间的距离的大小来判断的。与矢量量化(VQ)相比,LVQ最突出的特点就是其具有自适应性
1.向量量化
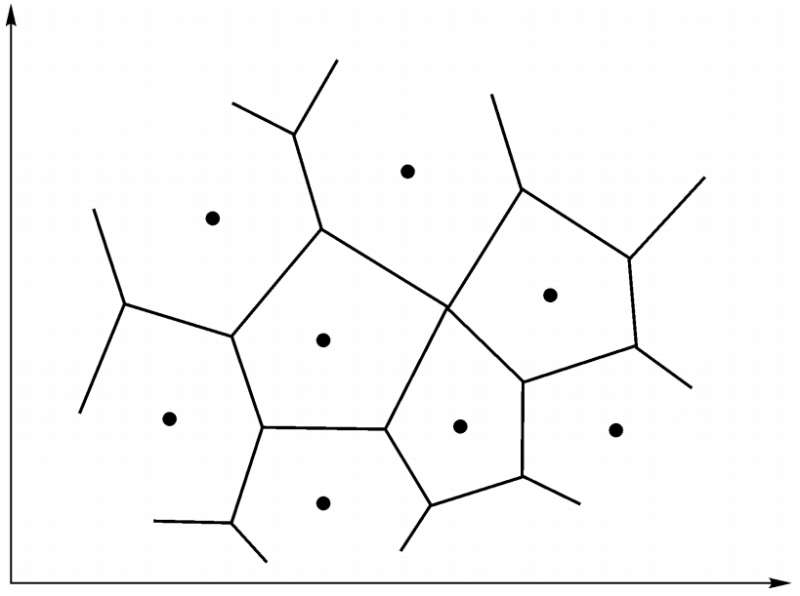
向量量化的思路是,将高维输入空间分成若干不同的区域,对每个区域确定一个中心向量作为聚类的中心,与其处于同一区域的输入向量可用该中心向量来代表,从而形成了以各中心向量为聚类中心的点集。在图像处理领域常用各区域中心点(向量)的编码代替区域内的点来存储或传输,从而提出了各种基于向量量化的有损压缩技术,在二维输入平面上表示的中心向量分布称为Voronoi图,如图所示:
自组织映射可以起到聚类作用,但无法直接分类或识别,因此它只是自适应解决模式分类问题两步中的第一步。第二步:学习向量量化,采用监督机制,在训练中加入信号作为分类信息对权值进行细调,并对输出神经元预先指定其类别。
2.学习矢量量化网络结构与工作原理
学习矢量量化神经网络有三层组成:输入层,竞争层,线性输出层。
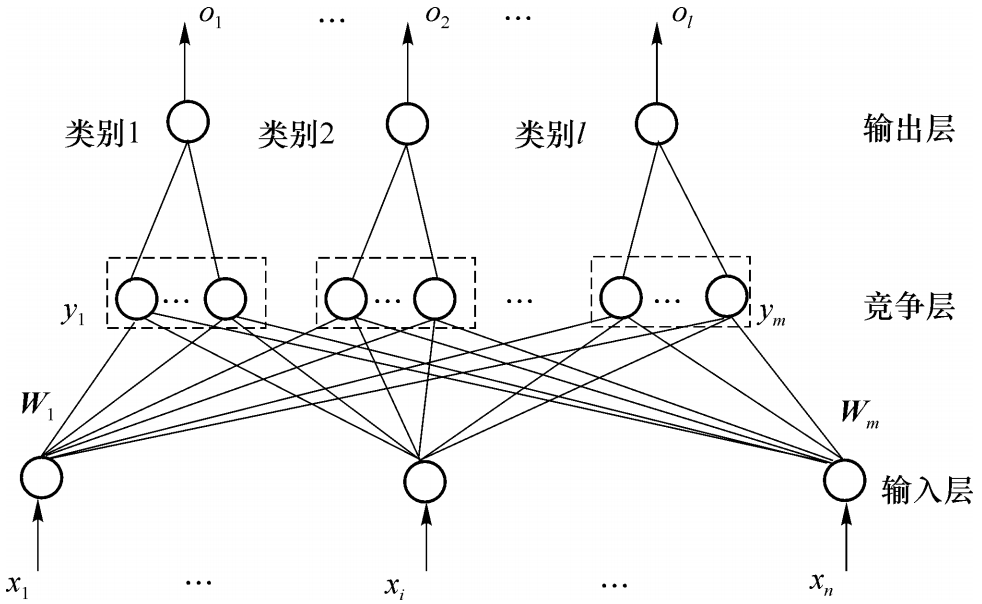
竞争层有m个神经元,输入层有n个神经元,两层之间完全连接。输出层每个神经元只与竞争层中的一组神经元连接,连接权重固定为1,训练过程中输入层和竞争层之间的权值逐渐被调整为聚类中心。当一个样本输入LVQ网络时,竞争层的神经元通过胜者为王学习规则产生获胜神经元,容许其输出为1,其它神经元输出为0。与获胜神经元所在组相连的输出神经元输出为1,而其它输出神经元为0,从而给出当前输入样本的模式类。将竞争层学习得到的类成为子类,而将输出层学习得到的类成为目标类。
3.学习矢量量化网络学习算法
学习矢量量化学习规则结合了竞争学习规则和有导师学习规则,所以样本集应当为{(xi,di)}。其中di为l维,对应输出层的l个神经元,它只有一个分量为1,其他分量均为0。通常把竞争层的每个神经元指定给一个输出神经元,相应的权值为1,从而得到输出层的权值。比如某LVQ网络竞争层6个神经元,输出层3个神经元,代表3类。若将竞争层的1,3指定为第一个输出神经元,2,5指定为第二个输出神经元,3,6指定为第三个输出神经元。则竞争层到输出层的权值矩阵为:
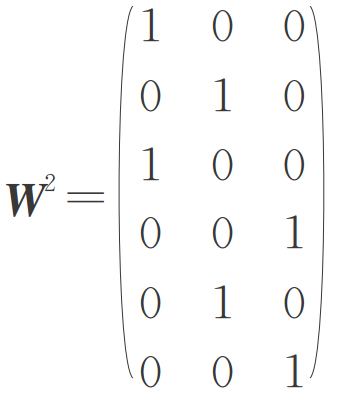
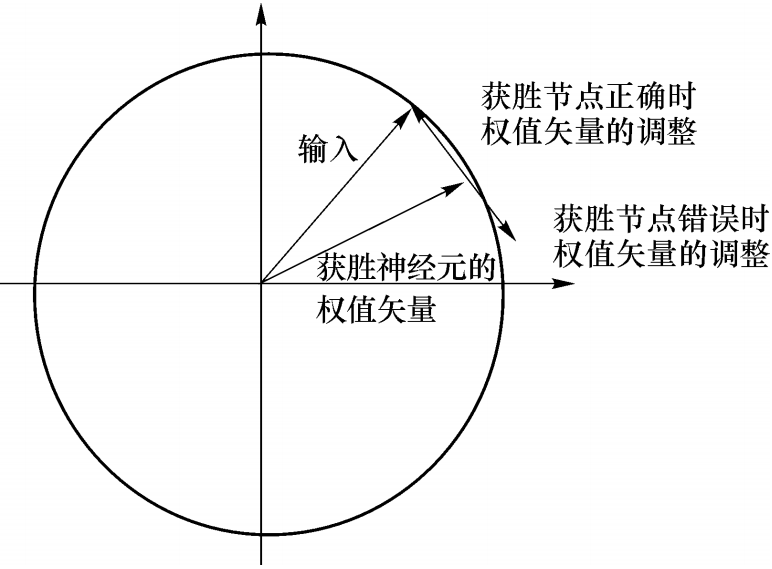
训练前预先定义好竞争层到输出层权重,从而指定了输出神经元类别,训练中不再改变。网络的学习通过改变输入层到竞争层的权重来进行。根据输入样本类别和获胜神经元所属类别,可判断当前分类是否正确。若分类正确,则将获胜神经元的权向量向输入向量方向调整,分类错误则向相反方向调整。
学习矢量量化网络学习算法的步骤如下:
初始化。竞争层各神经元权值向量随机赋值小随机数,确定初始学习速率和训练次数。
输入样本向量。
寻找激活神经元。
根据分类是否正确按照不同规则调整获胜神经元的权值,当网络分类结果与教师信号一致时,向输入样本方向调整权值:
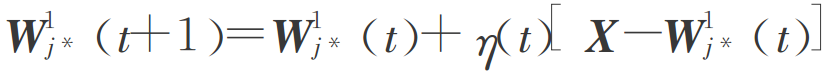
当网络分类结果与教师信号不一致时,向输入样本反方向调整权值:
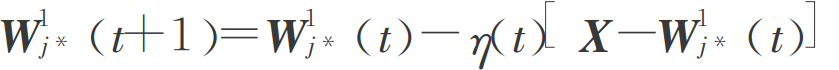
其他非激活神经元权值保持不变。
更新学习速率
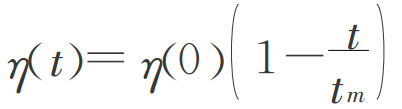
学习矢量量化网络是SOFM网络一种有监督形式的扩展,两者有效结合可更好地发挥竞争学习和有监督学习的优点。
连接方式:
输入层与竞争层之间采用全连接的方式,竞争层与线性输出层之间采用部分连接的方式。竞争层神经元个数总是大于线性输出层神经元个数,每个竞争层神经元只与一个线性输出层神经元相连接且连接权值恒为1。但是,每个线性输出层神经元可以与多个竞争层神经元相连接。竞争层神经元与线性输出层神经元的值只能是1或0。当某个输入模式被送至网络时,与输入模式距离最近的竞争层神经元被激活,神经元的状态为“1”,而其他竞争层神经元的状态均为“0”。因此,与被激活神经元相连接的线性输出层神经元状态也为“1”,而其他线性输出层神经元的状态均为“0”
基本步骤为:
初始化输入层与竞争层之间的权值W_ij及学习率η(η>0)。将输入向量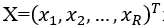 送入到输入层,并计算竞争层神经元与输入向量的距离:
送入到输入层,并计算竞争层神经元与输入向量的距离: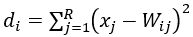 。
。
应用案例
|
 wechat
wechat alipay
alipay



