import argparse
import os
import matplotlib
matplotlib.use('AGG')
import matplotlib.pyplot as plt
import numpy as np
from keras.datasets import cifar10
from keras.layers import (Activation, Conv3D, Dense, Dropout, Flatten,
MaxPooling3D)
from keras.layers.advanced_activations import LeakyReLU
from keras.losses import categorical_crossentropy
from keras.models import Sequential
from keras.optimizers import Adam
from keras.utils import np_utils
from keras.utils.vis_utils import plot_model
from sklearn.model_selection import train_test_split
import videoto3d
from tqdm import tqdm
def plot_history(history, result_dir):
plt.plot(history.history['acc'], marker='.')
plt.plot(history.history['val_acc'], marker='.')
plt.title('model accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.grid()
plt.legend(['acc', 'val_acc'], loc='lower right')
plt.savefig(os.path.join(result_dir, 'model_accuracy.png'))
plt.close()
plt.plot(history.history['loss'], marker='.')
plt.plot(history.history['val_loss'], marker='.')
plt.title('model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.grid()
plt.legend(['loss', 'val_loss'], loc='upper right')
plt.savefig(os.path.join(result_dir, 'model_loss.png'))
plt.close()
def save_history(history, result_dir):
loss = history.history['loss']
acc = history.history['acc']
val_loss = history.history['val_loss']
val_acc = history.history['val_acc']
nb_epoch = len(acc)
with open(os.path.join(result_dir, 'result.txt'), 'w') as fp:
fp.write('epoch\tloss\tacc\tval_loss\tval_acc\n')
for i in range(nb_epoch):
fp.write('{}\t{}\t{}\t{}\t{}\n'.format(
i, loss[i], acc[i], val_loss[i], val_acc[i]))
def loaddata(video_dir, vid3d, nclass, result_dir, color=False, skip=True):
files = os.listdir(video_dir)
X = []
labels = []
labellist = []
pbar = tqdm(total=len(files))
for filename in files:
pbar.update(1)
if filename == '.DS_Store':
continue
name = os.path.join(video_dir, filename)
label = vid3d.get_UCF_classname(filename)
if label not in labellist:
if len(labellist) >= nclass:
continue
labellist.append(label)
labels.append(label)
X.append(vid3d.video3d(name, color=color, skip=skip))
pbar.close()
with open(os.path.join(result_dir, 'classes.txt'), 'w') as fp:
for i in range(len(labellist)):
fp.write('{}\n'.format(labellist[i]))
for num, label in enumerate(labellist):
for i in range(len(labels)):
if label == labels[i]:
labels[i] = num
if color:
return np.array(X).transpose((0, 2, 3, 4, 1)), labels
else:
return np.array(X).transpose((0, 2, 3, 1)), labels
def main():
parser = argparse.ArgumentParser(
description='simple 3D convolution for action recognition')
parser.add_argument('--batch', type=int, default=128)
parser.add_argument('--epoch', type=int, default=100)
parser.add_argument('--videos', type=str, default='UCF101',
help='directory where videos are stored')
parser.add_argument('--nclass', type=int, default=101)
parser.add_argument('--output', type=str, required=True)
parser.add_argument('--color', type=bool, default=False)
parser.add_argument('--skip', type=bool, default=True)
parser.add_argument('--depth', type=int, default=10)
args = parser.parse_args()
img_rows, img_cols, frames = 32, 32, args.depth
channel = 3 if args.color else 1
fname_npz = 'dataset_{}_{}_{}.npz'.format(
args.nclass, args.depth, args.skip)
vid3d = videoto3d.Videoto3D(img_rows, img_cols, frames)
nb_classes = args.nclass
if os.path.exists(fname_npz):
loadeddata = np.load(fname_npz)
X, Y = loadeddata["X"], loadeddata["Y"]
else:
x, y = loaddata(args.videos, vid3d, args.nclass,
args.output, args.color, args.skip)
X = x.reshape((x.shape[0], img_rows, img_cols, frames, channel))
Y = np_utils.to_categorical(y, nb_classes)
X = X.astype('float32')
np.savez(fname_npz, X=X, Y=Y)
print('Saved dataset to dataset.npz.')
print('X_shape:{}\nY_shape:{}'.format(X.shape, Y.shape))
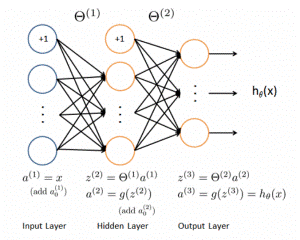
model = Sequential()
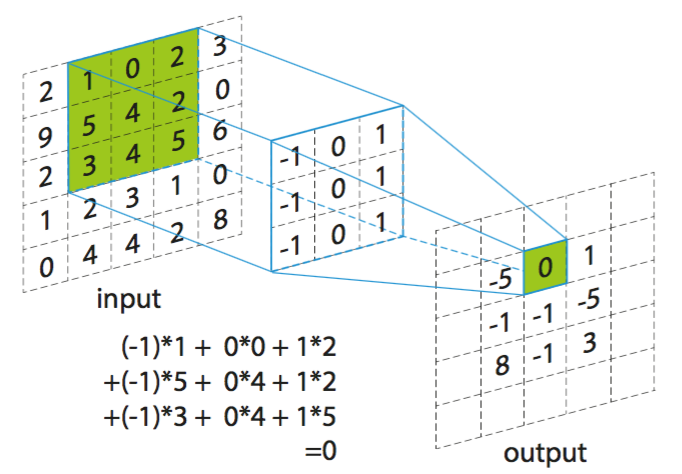
model.add(Conv3D(32, kernel_size=(3, 3, 3), input_shape=(
X.shape[1:]), border_mode='same'))
model.add(Activation('relu'))
model.add(Conv3D(32, kernel_size=(3, 3, 3), border_mode='same'))
model.add(Activation('softmax'))
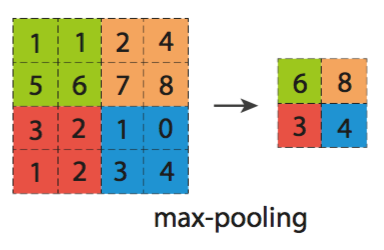
model.add(MaxPooling3D(pool_size=(3, 3, 3), border_mode='same'))
model.add(Dropout(0.25))
model.add(Conv3D(64, kernel_size=(3, 3, 3), border_mode='same'))
model.add(Activation('relu'))
model.add(Conv3D(64, kernel_size=(3, 3, 3), border_mode='same'))
model.add(Activation('softmax'))
model.add(MaxPooling3D(pool_size=(3, 3, 3), border_mode='same'))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='sigmoid'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes, activation='softmax'))
model.compile(loss=categorical_crossentropy,
optimizer=Adam(), metrics=['accuracy'])
model.summary()
plot_model(model, show_shapes=True,
to_file=os.path.join(args.output, 'model.png'))
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.2, random_state=43)
history = model.fit(X_train, Y_train, validation_data=(X_test, Y_test), batch_size=args.batch,
epochs=args.epoch, verbose=1, shuffle=True)
model.evaluate(X_test, Y_test, verbose=0)
model_json = model.to_json()
if not os.path.isdir(args.output):
os.makedirs(args.output)
with open(os.path.join(args.output, 'ucf101_3dcnnmodel.json'), 'w') as json_file:
json_file.write(model_json)
model.save_weights(os.path.join(args.output, 'ucf101_3dcnnmodel.hd5'))
loss, acc = model.evaluate(X_test, Y_test, verbose=0)
print('Test loss:', loss)
print('Test accuracy:', acc)
plot_history(history, args.output)
save_history(history, args.output)
if __name__ == '__main__':
main()
|

 wechat
wechat alipay
alipay







